Can you tell from a text whether the writer is happy? Angry? Disappointed? Can you put the writer鈥檚 happiness on a 1-5 scale?
By Tetsumichi (Telly) Umada
Course: Machine Learning and Linguistics (Ling 4100)
Advisor: Mans Hulden
LURA 2018
Sentiment analysis in computational linguistics is a general term for techniques that quantify sentiment or mood in a text. Robust tools for sentiment analysis are often very desirable for companies. Imagine that a company has just launched a new product GizmoX. Now the management wants to know how customers feel about it. Instead of calling or writing each person who bought GizmoX, if we could just have a program go on the web and find text on message boards that discuss GizmoX and automatically rate their attitude toward their recent purchase. Valuable information could be obtained, practically for free. Because sentiment analysis is used so widely for this purpose, it is sometimes called .
Of course, to be really accurate at analyzing sentiment you almost have to have a human in the loop. There are many subtleties in texts that computer algorithms still have a hard time with - detecting sarcasm, for example. But, for many practical purposes you don't have to be 100% accurate in your analysis for it to be useful. A sentiment analyzer that gets it right 80% of the time can still be very valuable.
Emoji Prediction
Emoji prediction is a fun variant of sentiment analysis. When texting your friends, can you tell their emotional state? Are they happy? Could you put an appropriate smiley on each text message you receive? If so, you probably understand their sentiment.
In this project, we build what's called a classifier that learns to associate emojis with sentences. Although there are many technical details, the principle behind the classifier is very simple: we start with a large amount of sentences that contain emojis collected from Twitter messages. Then we look at features from those sentences (words, word pairs, etc.) and train our classifier to associate certain features with their (known) smileys. For example, if the classifier sees the word "happy" in many sentences that also has the smiley , it will learn to classify such messages as听. On the other hand, the word "happy" could be preceded by "not" in which case we shouldn't rely on just single words to be associated with certain smileys. For this reason, we also look at word sequences, and in this case, would learn that "not happy" is more strongly associated with sadness, outweighing the "happy" part. The classifier learns to look at the totality of many word sequences found in a sentence and figures out what class of smiley would best characterize that sentence. Although the principle is simple, if we have millions of words of text with known smileys associated with the sentences, we can actually learn to do pretty well on this task.
, it will learn to classify such messages as听. On the other hand, the word "happy" could be preceded by "not" in which case we shouldn't rely on just single words to be associated with certain smileys. For this reason, we also look at word sequences, and in this case, would learn that "not happy" is more strongly associated with sadness, outweighing the "happy" part. The classifier learns to look at the totality of many word sequences found in a sentence and figures out what class of smiley would best characterize that sentence. Although the principle is simple, if we have millions of words of text with known smileys associated with the sentences, we can actually learn to do pretty well on this task.
If you don鈥檛 want to actually re-create the classifier, you can skip ahead to the Error Analysis section where you'll see how well it does in predicting 7 different smileys after being "trained" on some text.
Technical: Quickstart
To use this project, it's required to install python3, jupyter notebook, and some python libraries.
Install
Install python3
If you don't have python3 on your computer, there are two options:
- Download python3 from , which includes Python, Jupyter Notebook, and the other libraries.
- Download python3 from
Install packages
All packages used for this project are written in requirements.txt. To install, you can run
$ pip3 install -r requirements.txt
听
Download project
To download this project repository, you can run
$ git clone
听
Run jupyter notebook
To start jupyter notebook, you move to the directory with cd path_to/text2emoji, then run
$ jupyter notebook
Project Details
The goal of this project is to predict an emoji that is associated with a text message. To accomplish this task, we train and test several supervised machine learning models on a data to predict a sentiment associated with a text message. Then, we represent the predicted sentiment as an emoji.
Data Sets
The data comes from the . Since the file format is a pickle, we wrote a python 2 script to covert a pickle to a txt file. The data (both pickle and txt files) and scripts are stored in the text2emoji/data directory.
Among the available data on the repository, we use the PsychExp dataset for this project. In the file, there are 7840 samples, and each line contains a text message and its sentimental labels which are represented as a vector [joy, fear, anger, sadness, disgust, shame, guilt].
In the txt file, each line is formatted like below:
[ 1. 0. 0. 0. 0. 0. 0.] Passed the last exam.
听
Since the first position of the vector is 1, the text is labeled as an instance of joy.
For more information about the original data sets, please check and text2emoji/data.
Preprocess and Features
How does a computer understand a text message and analyze its sentiment? A text message is a series of words. To be able to process text messages, we need to convert text into numerical features.
One of the methods to convert a text to numerical features is called an . An n-gram is a sequence of n words from a given text. A 2-gram(bigram) is a sequence of two words, for instance, "thank you" or "your project", and a 3-gram(trigram) is a three-word sequence of words like "please work on" or "turn your homework".
For this project, first, we convert all the texts into lower case. Then, we create n-grams with a range from 1 to 4 and count how many times each n-gram appears in the text.
Models and Results
Building a machine learning model involves mainly two steps. The first step is to train a model. After that, we evaluate the model on a separate data set---i.e. we don't evaluate performance on the same data we learned from. For this project, we use four classifiers and train each classier to see which one works better for this project. To train and test the performance of each model, we split the data set into a "training set" and a "test set", in the ratio of 80% and 20%. By separating the data, we can make sure that the model generalizes well and can perform well in the real world.
We evaluate the performance of each model by calculating an accuracy score. The accuracy score is simply the proportion of classifications that were done correctly and is calculated by
For this project, we tested following classifiers. Their accuracy scores are summarized in the table below.
| Classifier | Training Accuracy | Test Accuracy |
| 0.1458890 | 0.1410428 | |
| 0.9988302 | 0.5768717 | |
| 0.9911430 | 0.4304813 | |
| 0.9988302 | 0.4585561 |
Based on the accuracy scores, it seems like SVC works, but gives poor results. The LinearSVC classifier works quite well although we see some overfitting (meaning that the training accuracy is high and test accuracy is significantly lower). This means the model has difficulty generalizing to examples it hasn't seen.
We can observe the same phenomenon for the other classifiers. In the error analysis, we therefore focus on the LinearSVC classifier that performs the best.
Error Analysis
We analyze the classification results from the best performing (LinearSVC) model, using a confusion matrix. A confusion matrix is a table which summarizes the performance of a classification algorithm and reveals the type of misclassifications that occur. In other words, it shows the classifier's confusion between classes. The rows in the matrix represent the true labels and the columns are predicted labels. A perfect classifier would have big numbers on the main diagonal and zeroes everywhere else.
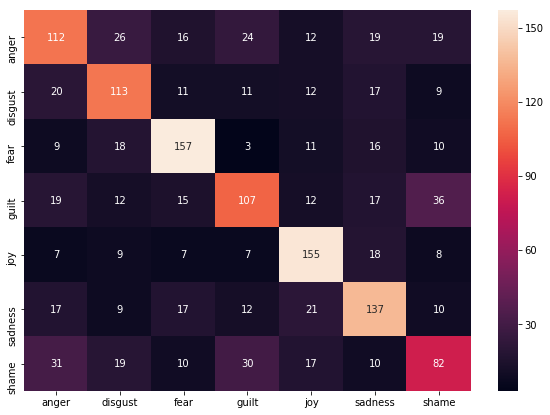
It is obvious that the classifier has learned many significant patterns: the numbers along the diagonal are much higher than off the diagonal. That means true anger most often gets classified as anger, and so on.
On the other hand, the classifier tends to often misclassify text messages associated with guilt, shame, and anger. This is perhaps because it's hard to pinpoint specific words or sequences of words that characterize these sentiments. On the other hand, messages involving joy are more likely to have words such as "good", "like", and "happy", and the classifier is able to handle such sentiments much better.
Future Work
To improve on the current results, we probably, first and foremost, need access to more data for training. At the same time, adding more specific features to extract from the text may also help. For example, paying attention to usage of all caps, punctuation patterns, and similar things would probably improve the classifier.
A statistical analysis of useful features through a Chi-squared test to find out more informative tokens could also provide insight. As in many other tasks, moving from a linear classifier to a deep learning (neural network) model would probably also boost the performance.
Example/Demo
Here are four example sentences and the emojis the classifier associates them with:

References
Tetsumichi (Telly) Umada
 Tetsumichi (Telly) Umada is majoring in both computer science and linguistics at the 麻豆影院. He is an avid bike rider and loves researching involving human languages and computers, such as artificial intelligence, machine learning, and natural language processing.听
Tetsumichi (Telly) Umada is majoring in both computer science and linguistics at the 麻豆影院. He is an avid bike rider and loves researching involving human languages and computers, such as artificial intelligence, machine learning, and natural language processing.听